Multilingual Models KAI
This project corresponds to AI Platform's Generative AI & Knowledge AI MLOps journey.
Project Goals
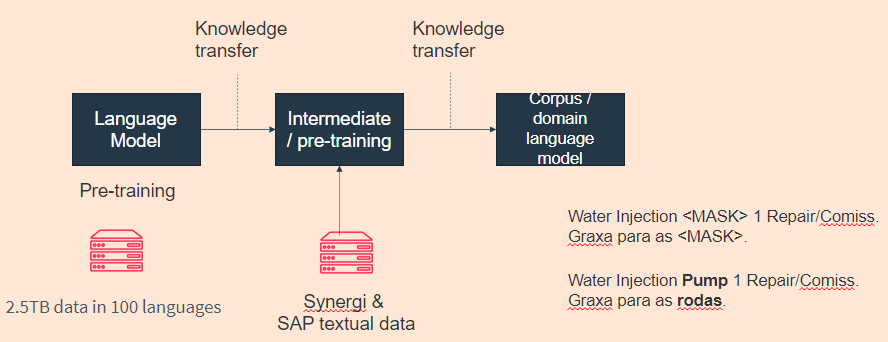
The multilingual models are trained and fine-tuned Brazilian-Portuguese ML models for equipment entity extraction. These models are used by Operational Planning Tool (OPT) in Equinor.
OPT is a cloud-based software which pulls in the most important information for operations from different sources, like for example Safran planner, TIMP, Well Risk, Synergi and SAP, to name a few. It is one of the most important tools for planning risk analysis and is already implemented in most operating fields in Norway.
They seek to answer following questions for Equinor maintenance personnel:
(1) Have incidents occurred while performing similar tasks on this equipment type?
(2) What incidents occurred in the past when performing work on this equipment in this location?
You can find more information about OPT multilingual models here:
https://statoilsrm.sharepoint.com/:p:/r/sites/DAMteamprivate/Shared%20Documents/Gas%20Squad%20Whale/Reviews%20and%20presentations/Data%20Day/KAI_NLP_dataday22.pptx?d=w0b69c93b02294c3ab85c7d0ed2851b1a&csf=1&web=1&e=6QckLg
Summary of Results
Through data visualisation, OPT helps us see the full risk picture, in one place, when planning and executing jobs offshore. Then we can better understand and manage our risks and improve efficiency. We can reduce risks associated with non-ideal planning of critical offshore activities and changes of plans. Further, it enhances learning from incidents across installations: OPT help our planners, discipline leaders and engineers improve risk management by linking planned activities to lessons learned from the past.
Previously, our operational planners had to access several different systems to find all the relevant information. But now they can go into the OPT dashboard to find all the information they need quickly.
Project Team
Jennifer Sampson (Data Scientist)
Peter Koczca (Data Scientist)
MLOps Challenges
Large Compute Requirement
It is not feasible to train these NLP models using large amount of training data on the local machine.
Long Training Time for Model Training
These complex NLP models take a long time to train using traditional CPU compute.
Need for Distributed Model Training
Need to process Pytorch jobs using multiple workers for distributed training using deepspeed model training and inference framework
Need to Store and Accesss Large Amount of Training Data
Large amount of training data needed to be stored in cloud and then needed to be available for training in a distributed training environment.
MLOps Solutions
GPU Compute on Kubernetes Cluster
Team was able to make use of GPU compute on Kubernetes to leverage the scale and power of kubernetes to process the ML model training jobs.
Speeding Up Model Training using GPU
Team was able to reduce the time it takes to train the model using distributed training, powerful GPU compute and scalability of Kubernetes.
Persistent Data Storage & Availability
Team was able to store large amount of training data on Persistent Volumes on Kubernetes and readiliy make it available to training jobs in a distributed training environment using multiple workers.
GitHub Repos
https://github.com/equinor/kai-multilingual-models