Dip Picking
This project corresponds to AI Platform's Computer Vision MLOps journey.
Project Goals
In June 2022, a collaboration with the Geo Operations Center was initiated, to produce a proof of concept (POC) to evaluate the feasibility of developing an integrated solution that automatically identifies and calculates stratigraphic dips from azimuthal density images in real-time during the drilling of production wellbores (LWD data). For more information on the project, visit the project repo.
Summary of Results
The team created a workflow to generate synthetic borehole image logs and trained a deep convolutional neural network that is capable of detecting sinusoidal features in image logs. Results presented in June 2023 were accepted to be of good quality by GoC operators and approval was given to deploy the model to be used in well placement (geostreering) operations. The team was able to conduct rapid experimentation while collaborating effectively using a suite of MLOps tools on AI Platform. Once the model was trained, the project team was also empowered to quickly deploy the trained model using the KServe model serving framework to serve the model across Equinor users using REST API endpoints.
Project Team
Kivanc Biber (Data Scientist)
Isabella Masiero (Scrum Master)
Ole Finn Tjugen (Subject Matter Expert)
Prerit Shah (MLOps Architect)
Matt Li (Model Deployment)
MLOps Challenges
Complex Depencies / Virtual Environment Setup
Dip picking project uses an object detection and segmentation framework called Masked Regional Convolution Neural Network (MRCNN) (original paper here). A python implementation of the said framework was chosen (link to mrcnn repo). However, this package has not been very well maintained and thus it required manual editing of certain files inside the installed MRCNN Python package file (mainly to make use of Tensorflow 2 architecture). Because of the long list of manual interventions to set up compute environment, it was very difficult for new data scientists to start contributing towards the projects. Even when their environment was set up, it could easily break (especially when they needed to install different packages during development/experimentation phase). Moreover, prior to adopting AI Platform, project data scientists were doing their development in tightly controlled VM environment where they could not even install a new Python package using Pip on their own. Because of the difficulties and overhead due to being dependent on DevOps personnel, version control best practices were not adopted. This resulted in siloed work, and will have caused many headaches of integrating code later on.
Long Training Time for Model Training
Prior to partnering with AI Platform, the team was struggling with long runtimes for model training. It took a very long time to run train their models using CPUs (on the order of days) to get sufficiently good trained models.
Lack of Experiment and Model Tracking Ability
While developing their models,the team needed to run countless experiments with multiple datasets and hyperparameter configurations to find the best combination of input parameters and datasets. This was a large undertaking to track all of the moving parts related to model develeopment. They lacked tools, resources and expertise to track their data, experiments, hyperparameters, performance metrics, and models properly to generate reproducible results. Often times, data scientists had to rely on Power Point slides to track their experiment metadata and results.
Not Easy to Perform Hyperparameter Tuning
The project code was entirely contained in Jupyter notebook and non-modular nature of the code made it difficult to implement Hyperparameter tuning (without extensive code restructuring) with some standard open source libraries such as Hyperopt. It was not very feasible for project team to spend so much time in code restructuring at this crucial phase of Proof of Concept.
MLOps Solutions
Project Specific Jupyter Notebook Server Image
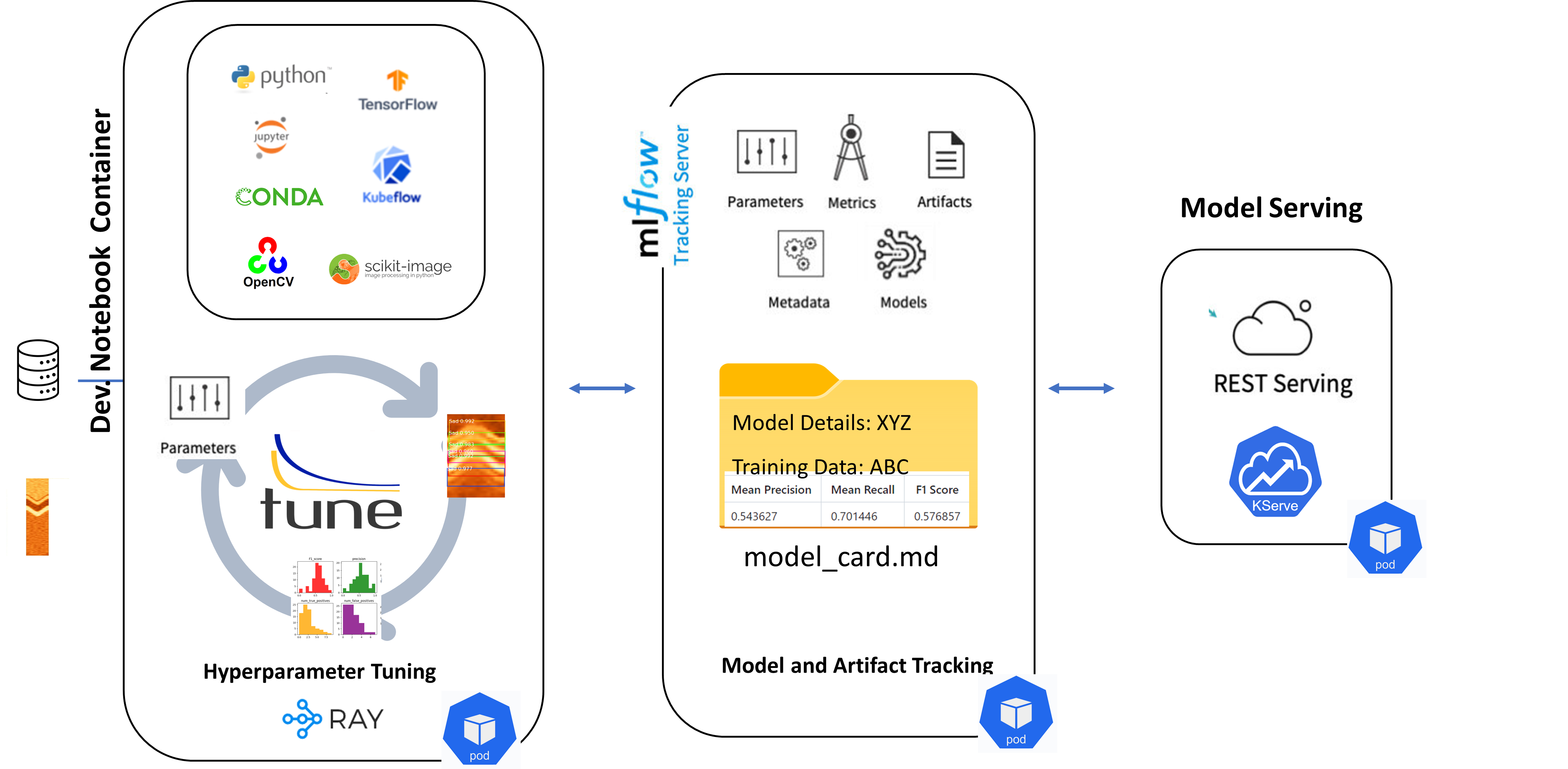
MLOps team created a project specific Jupyter Notebook Server Image that contained all the project specific Python packages and other dependencies including conda virtual environments that can be used a Jupyter Notebook Kernel. This meant that they didn't need to spend any time to reconfigure compute environment from scratch each time it got accidentally corrupted (simply by stopping and starting the notebook.). It also helped new team members to start coding within matter of minutes (this was very appreciated when a new summer student joined the team and she was contributing on day one rather than). More specifically the Notebook Server Image contained instructions to:
- install all dependencies (some more complicated than others like open-cv, tensorflow, M-RCNN)
- modify specific source code to make some older packages compatible with newer ones
- install and configure
- Create a conda virtual environment
- add kernel to ipyhthon
Boosted Team Collaboration Project Specific Kubeflow Profile
Thanks to some of the AI Platform-enabled tools such as GIT/GITHUB integration, persistent storage volumes, Tensorboard server, namespace segregation, experiment tracking, pipelines etc. The team received a collaboration boost and prevented integration challanges down the road.
Every member of the project team had their own kubeflow profile where they can run their own private experiments, notebooks and pipelines. In addition, project specific Kubeflow profile was setup in which all team members could seamlessly collaborate for running their notebooks, sharing data, executing pipelines and deploying models.
Speeding Up Model Training using GPU
Team was able to speed up their model training by 30 times using Jupyter Notebook Server powered by GPUs. Team was also able to minimize the cost incurred by GPU usage by seamlessly switching between CPU and GPU notebooks while code/data resided on the data volume that was mounted on both. GPU notebooks were used only when actual model training needed to be run. Else, CPU notebooks (with minimal resources) were used during code writing and development.
Scalable and Flexible Compute
In addition to having access to GPU hardware, team was able to leverage flexible and scalable compute as per required CPU, GPU and RAM.
Experiment and Model Tracking
Team was able to track their multiple experiments and models effectively using MLflow in Kubeflow while using their Jupyter notebooks in Kubeflow. This process greatly improved efficiency of the team by eliminating the need to manually track their experiments which was very burdensome.
Easily Deploy Trained Models using KServe
Team was able to quickly, seamlessly and efficiently deploy their trained deep neural network models as a REST API endpoint on Kubernetes cluster using KServe serverless framework.
A great benefit of KServe framwork is that the deployed models can have features like autoscaling or scale to zero capability. That means if prediction request traffic increases, then more workers will be automatically added and if there is no request for a prediction, then the workers will to shut down to zero, efectively costing nothing when there are no requests. Opening doors for significant cost savings while not sacraficing any performance.
Model Monitoring and Prediction Tracking
Team could also track predictions generated from deployed model endpoints using MLflow instance deployed in Kubeflow. Each model version becomes an inference experiment and each prediction generated is stored as an inference run under that experiment.
GitHub Repos
Training/Experimentation:
https://github.com/equinor/image-log-dip-extractor
Deployment:
https://github.com/equinor/image-log-dip-extractor-deployment
Dip-Picking Development Architecture
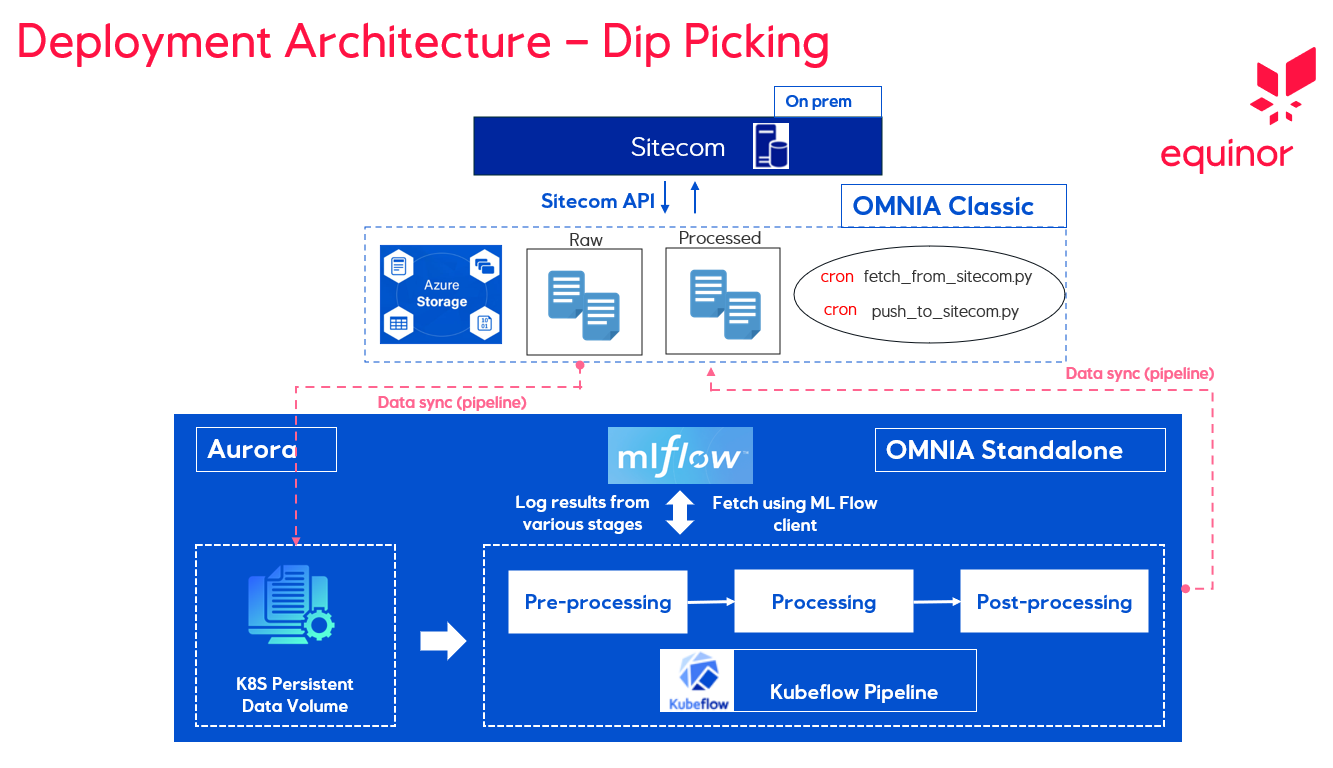
Dip-Picking Deployment Architecture